Generalised Specificity
Why the best AI agents do less — and why that's the point
Everyone is building AI agents. Most of them don't work.
Not because the technology isn't ready. Not because the teams aren't smart. But because of a design philosophy error that I see repeated constantly: the belief that a more capable agent is a more valuable one.
It isn't.
The failure pattern
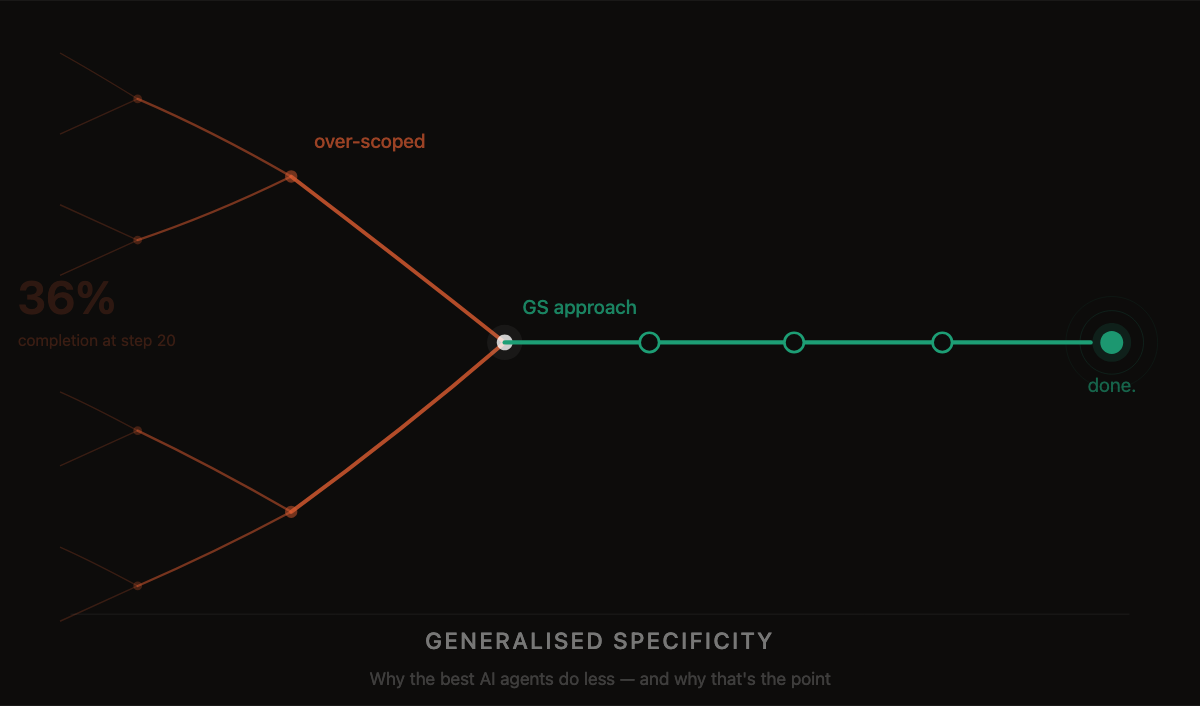
The data is striking. 42% of companies abandoned most of their AI initiatives in 2024, up from just 17% the year before. The average organisation scrapped 46% of AI proof-of-concepts before they reached production.
When you look at why, a pattern emerges. Organisations are failing for three main reasons: a poorly scoped vision for agentic workflows, a poor technical solution, and a lack of focus on change management. And of these, scope is the most common culprit. Teams build agents that try to do too much.
There is a brutal compounding mathematics problem here. Even if you assume each step in an agent workflow succeeds 95% of the time, a 20-step workflow only has about a 36% chance of completing without error. Production systems for critical processes aim for 99.9%+ reliability. The gap between those two numbers is where AI agent projects go to die.
The consequences are not theoretical. In mid-2025, an AI coding assistant made headlines after it deleted a company's production database during a code freeze, despite being explicitly instructed not to touch production. A system given too much scope and too little constraint will eventually do something catastrophic.
The first question should always be: can we start with a single, specific agent?
The belief that a more capable agent is a more valuable one. It isn't.
The philosophy that works
My team has been building and deploying AI agents at GoCardless for the past year. We set ourselves a target of six agents. We've delivered nine, with more in the pipeline. Every single one follows the same design principle, which I've come to call Generalised Specificity.
The idea is simple: build an agent that does one specific thing as generalisably as possible.
Not an agent that handles all financial reporting. An agent that produces the monthly FinCrime report — reliably, every time, in exactly the right format, with the right data, for the right audience.
Not an agent that answers any question about the product. An agent that handles product feature queries through a defined conversational interface.
Not a performance agent. A daily revenue insight agent that pushes to Slack.
Each agent in our suite is narrow in scope and wide in applicability. None of them tries to be everything. All of them do their job with high reliability — because reliability was the design goal, not capability breadth.
The pattern in the organisations that are succeeding is consistent: bounded scope, human oversight, specific workflows. Not moonshot attempts at general intelligence — pragmatic augmentation that delivers measurable impact.
The orchestration unlock
Once you build agents this way, something interesting happens to the orchestration problem.
Orchestration sounds intimidating — coordinating multiple agents, managing handoffs, maintaining state across a complex workflow. In practice, if your agents are well-designed under the GS principle, the orchestration layer becomes relatively static. Each agent has a clean contract: defined inputs, a single job, predictable outputs. The routing logic between them doesn't need to be intelligent. It needs to know when to call which agent and what to pass it. That is a well-understood engineering problem, and platforms already solve it.
Google Vertex AI's Agent Development Kit, AWS Bedrock Agents, Microsoft Azure AI Foundry, and open-source frameworks like LangGraph and CrewAI all handle the orchestration layer competently. The choice between them is largely a question of which cloud ecosystem you're already in. For most teams, this is not the hard problem.
The more important insight is what Generalised Specificity does to your relationship with the underlying AI models themselves.
The pace of development in foundation models right now is extraordinary. The model that was state-of-the-art six months ago may not be the right choice today. Most teams building AI agents are tightly coupling their agents to a specific model — which means every time a better model appears, they face a painful rebuild.
GS breaks that coupling. Because the agent is the interface and the logic — not the model — the model becomes the engine, and engines are replaceable. When something better comes along, you swap it in, test it against the agent's defined quality bar, and if it passes, you're done. Nothing rebuilt. Just an upgraded engine.
This is plug-and-play AI.
The model is the engine. Engines are replaceable. This is only possible if the agent was designed with a clear enough scope that you can define what 'better' actually means.
The harder problem
I want to be honest about what Generalised Specificity doesn't solve.
Once you have a suite of well-designed, narrowly scoped agents, you still have the question of behavioural coherence at scale. How do you ensure that as the number of agents grows, the estate stays consistent — in tone, in quality, in how it represents your organisation? An agent that is 10% more accurate but 30% off-brand is not a net improvement.
This is the orchestration problem that isn't solved by routing logic. It's solved by shared system prompt layers, behavioural guardrails applied across the estate, and clear ownership of what 'good' looks like for every agent, consistently defined.
Getting this right is, in my view, where the real intellectual challenge in agent deployment currently lives.
Generalised Specificity is the foundation. Coherence at scale is the next frontier.
A practical starting point
If you're building AI agents — or trying to rescue a programme that's stalling — three questions will tell you most of what you need to know.
Can you describe what this agent does in one sentence, without the word 'and'? If not, it's trying to do too much.
Do you know exactly what good output looks like before you start building? Successful implementations have crystal-clear documentation of their current processes before writing a single line of code. They know exactly what good looks like.
Is the value of getting this right worth the complexity of building it autonomously? Sometimes a well-structured template and a human analyst is the better answer. Build the agent when the reliability bar is achievable and the volume justifies the investment.
The best AI agents we've built are, in one sense, boring. They do a specific thing. They do it reliably. They will do it again tomorrow. They let you swap the engine when a better one arrives.
That's not a limitation of ambition. That's the architecture.
Prince writes about AI, data strategy, and building teams.
